|
Background
During the past 22 years the museum has grown in size and complexity and thus has become a complicated project for anyone to carry on the work after the author has to bow to the pressures of age. The unexpected happens which is why we back-up files with multiple copies in several physical locations. The human equivalent of a back-up is documentation.
The author has a background in text processing for commercial publishing. The essential difference between a standard database and a database for reference book production was the need to store multiple paragraphs of text as a single field and to be able to retrieve them quickly for editing. Commercial database systems that stored text as linked files could, in the 1990s, take many seconds to load the text for editing. This slowness had considerable cost implications.
In the 1970s system designers recognised the need to store data in a neutral format that could be processed into multiple output formats. This was generic coding and SGML HTML and XML eventually emerged. However, initially SGML was unattractive for small and medium size projects due to the high cost of producing the DTD (Data Type Declaration) and associated editor with embedded checking against the DTD.
Up until the late 1970s all UK typesetting required a skilled unionised keyboard operator to re-key all material. Typically financial rewards were based on the output rate and the keyed material was encoded for a particular typesetting system, mechanical or photographic. Essentially a linear stream of characters both text and machine commands was generated on paper tape. For speed the typesetting commands were the minimum required and one error would cascade down several paragraphs. Additionally each operator would have their own way of working the command sequences.
In the early 1980s with the appearance of word processors in publishing offices there became irresistible pressure to use publisher keyed data directly. The majority of printing companies who responded to the challenge taught their customers to use mnemonics for the typesetting commands - replicating the keyboard operator's mode of working and locking the customer to a single output route. Typesetting systems supplied search and replace software to replace the mnemonics with the machine code required.
By taking the approach of logically tagging material, via a markup language, according to the type of information (e.g. main heading, sub heading and text) in place of specific machine instructions the data became output format independent. This required the angle brackets on the keyboard to be used only to bracket the tags and not to be used as part of the text. With simple checking software the expensive output route was taken only when the data was sensibly error free. Making the concept work required computer programming and not a reliance on a simple search and replace program. A commercial advantage flowed from the concept.
Finally there was the need to be able to access from a simple QWERTY keyboard the full range of characters required by the publisher. By using the square brackets and braces as control characters, super-cases could be added to the basic ASCII. Once entered, many characters from the super-case could be keyed and the sequence ended with the close character.
All of the above generic data concepts are featured in the data structures of the Valve Museum for both text and database fields.
All text editing is made with a text editor using a constant width font. This ensures that all the tags on the left side range. This reduces eye strain.
Pi Characters and Links
A pi character can be defined as anything outside the basic ASCII set. The museum data uses standard HTML characters where appropriate and takes inferior and inferior fonts from a super-case. Characters from the ASCII set used as controls must not appear in a text file.
ASC(34) often used casually as a double quote is never used in the raw files. Quoted material is enclosed with an apostrophe front and rear. The keyboard prime character ′ is never used in the raw files. The html entities for single and double prime are safe to use but are generally not required. The forward slash / is used directly from the keyboard but the backslash \ is reserved as a control character and must not be used within a field.
Inferior characters as in H2O open with {*D^ followed by one or many characters and terminated by }.
Superior characters as in x2 open with {*U^ followed by one or many characters and terminated by }.
A non breaking space or thin space used to separate values from units is represented by [k] a sequence first used in 1982.
Within a text paragraph highlighting is restricted to the use of italic for example 〈i〉See also〈/i〉.
Field tags are typed between 〈 and 〉 as in 〈=NAME=〉 and each field is terminated with a backslash \.
To keep internal links as general as possible they are keyed in the form {target^description} and expanded by software.
Exhibit Database
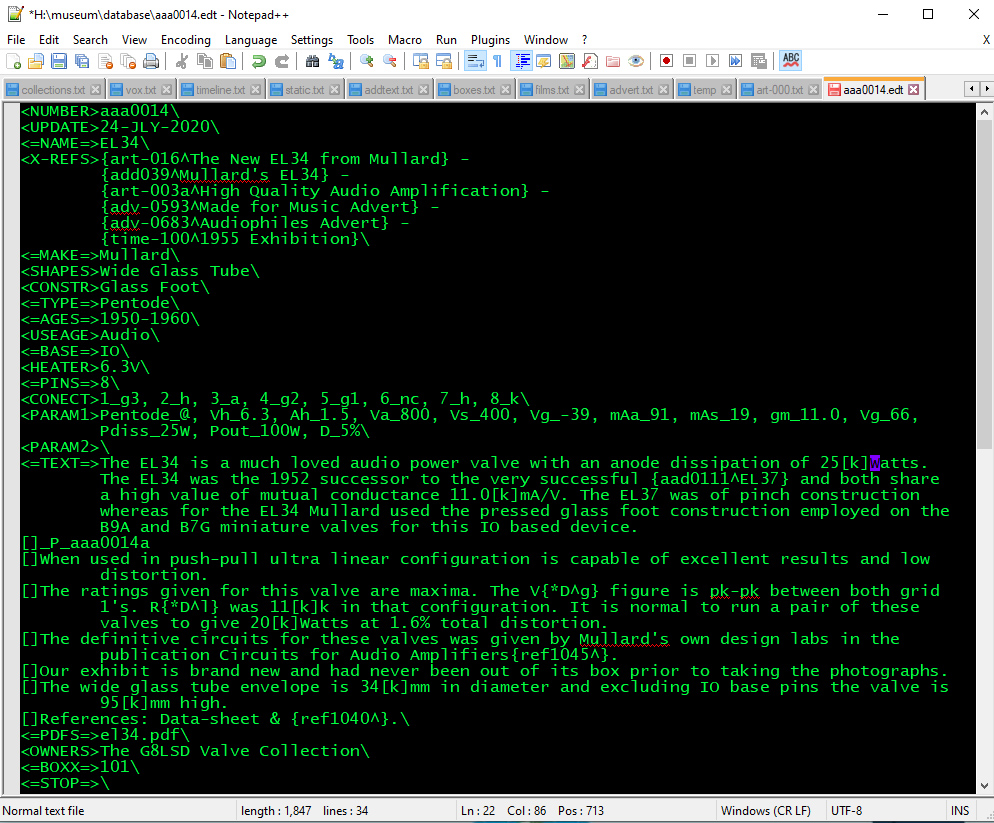
Exhibit database example text file.
In the database directory there are thousands of individual text files, one per exhibit, of the format seen above. The control program requests a unique reference - aaa0014 - for the above example. Notepad++ is loaded plus the text file. Access is seemingly instantaneous. Once editing is completed the file is saved, closed and the editor exited. The control program then passes the text file through the database build routines where fields with index terms are checked for compliance with the validation file list.
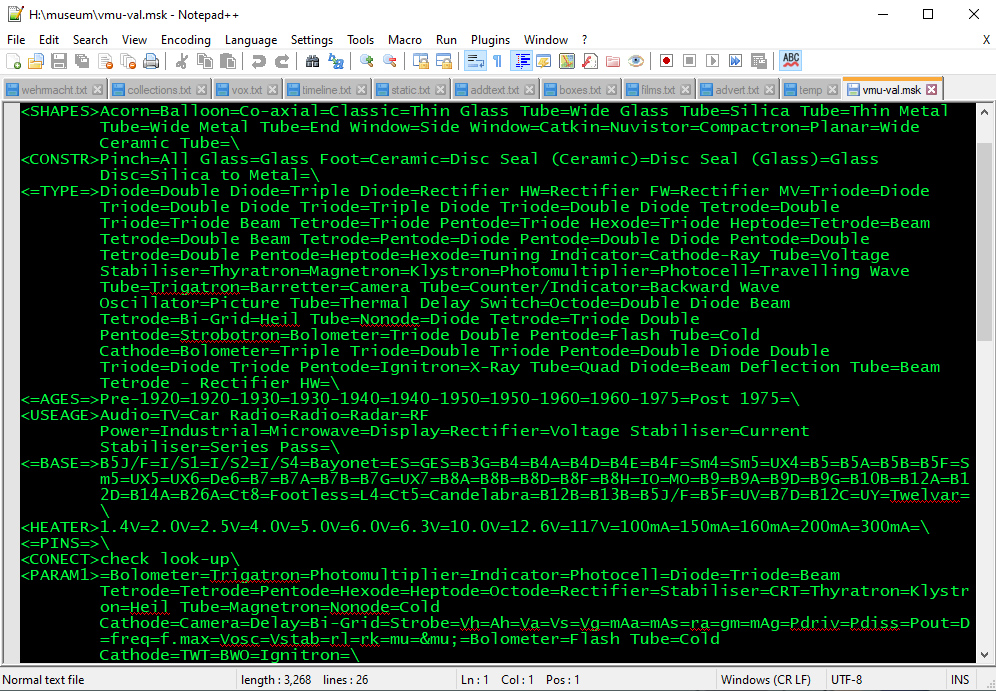
Part of the index validation file.
A file where all the terms are contained in the validation file is passed as clean and control returns to requesting the next unique reference. If errors are found, an error file is written and notepad++ opened for review.
In database terms these sets form tuples or closed sets of items. In mathematical terms the terms would be separated by commas, here we use = signs. To add a new term the list is extended and the new list is used by the validator on the next run be it a full database build or a single edited entry.
〈NUMBER〉 the unique database key. The three letters identify the collection and the four digits are a simple numerical sequence within that collection. The Type designation cannot be regarded as unique.
〈UPDATE〉 the date last edited.
〈=NAME=〉 the Type designation.
〈X-REFS〉 links to appear in the exhibit heading box.
〈=MAKE=〉 name of Manufacturer - validated at database build to link to the make/brand database.
〈SHAPES〉 the validated index term for envelope shape
〈CONSTR〉 the validated index term for the basic construction.
〈=TYPE=〉 the validated index term for the electrode system.
〈=AGES=〉 the validated index term for the decade of introduction.
〈USEAGE〉 the validated index term for the design application.
〈=BASE=〉 the validated index term for the base cap type.
〈HEATER〉 the validated index term for the heater voltage or current.
〈=PINS=〉 the validated index term for the maximum number of base pins.
〈CONECT〉 a compound field of n sub-fields giving pin usage. The format is pin number_function followed by comma space.
〈PARAM1〉 the primary parameters entered as a set of sub-fields.
〈PARAM2〉 secondary parameters typically used for valves with two sections e.g. triode pentode.
〈=TEXT=〉 the main free text description area. New paragraphs are indicated by starting a line with []. Picture calls are represented by a paragraph that starts with _P_ followed by the image name.
〈=PDFS=〉 a field with a single PDF name used for the data-sheet only.
〈OWNERS〉 a text description of the collection name for convenience only.
〈=BOXX=〉 the storage location of the physical exhibit.
〈=STOP=〉 the end record marker that must be present.
All exhibit database records must commence with NUMBER and conclude with =STOP=. The database build software reads the text file character by character and reduces the character to seven bits - a legacy of editing with Wordstar. Each field is built in memory and the index fields validated. The field sequence is as above for consistency but the software does not demand a sequence beyond the first and last tags.

The exhibit template file.
For ease of use and consistency of structure there is a blank template file. For a new exhibit the control program will generate a file where only the main key and update date fields are present. The template is then cut and pasted into the new file and populated. The rest of the file contains temporary information and a list of collection names.
Articles Etc.

An example of an article text file.
Articles, additional technical features, timeline articles, recollections, collection descriptions and basic unchanging material are held as separate files in a single directory. All the files have a common structure and are converted by a program that reads the file list in the directory and processes each in turn.
Every article is treated as a single record however long the text.
〈articl〉 this is the opening tag and together with 〈=stop=〉 must be present together with the end field character backslash. The filename is the text of the article tag. Other fields are optional and so can appear zero, one or many times.
〈titles〉 this is always present.
〈=from=〉 this cites the source by author, publication and date.
〈extras〉 this field is for links that appear in the right side menu in the current format. They represent additional items related to but not part of the present article.
〈=text=〉 a paragraph of text terminated by a backslash. These paragraphs can contain n links or a picture call. The html typographic controls are used to further indicate headings or body text; the definitions of which are in an external CSS file.
Where tables appear in an article these can be as images or direct HTML.
Picture calls appear in a separate paragraph as {img-1-999-art007b^art007b} where -1-999- indicates a border width of 1 px and an image of original size. The border can be 1 or a 3, 3 is used where the picture is a link to a second file. The image height can be set as required by changing the 999 to, say, 400. The image name follows plus the sub field indicator ^. The second link is optional and in most cases is not required.
Captions are denoted by the use of h6.
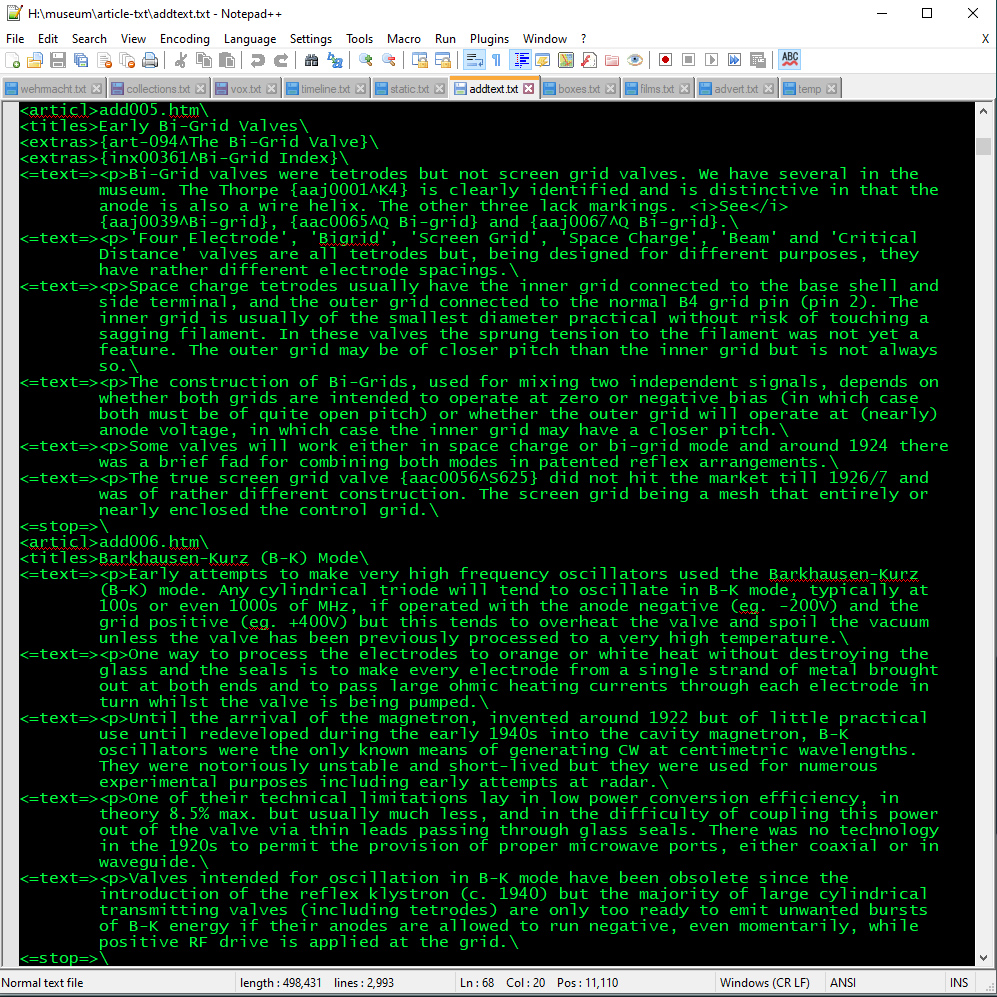
A sample from the additional technical features file.
The additional technical features are all held within a single text file. The 〈articl〉 tag denotes the start and filename. 〈=stop=〉 marks the end of an individual output file.

Part of the collections introductions file.
The description of the origin of each collection is maintained in this file. The structure is the same as the additional technical features file and resides in the articles-text directory.
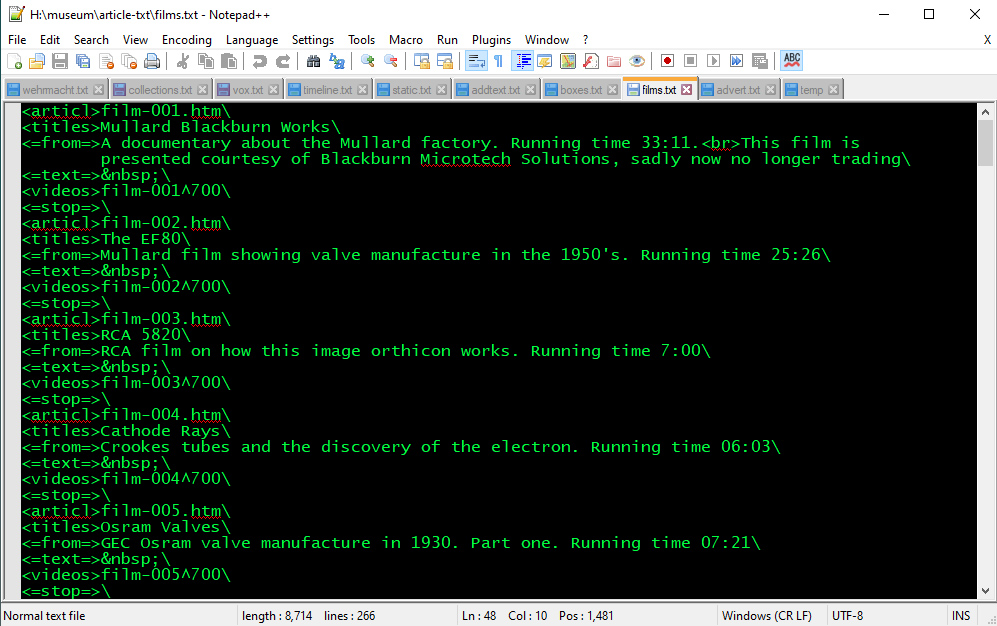
Part of the file that generates the films output files.
The 〈videos〉 tag always has two sub fields separated by ^, filename and image size.
Part of the static.txt file showing manufacturer details.
The file static.txt houses a range of material from manufacturer descriptions to general notes files. The structure follows the general pattern.
Part of the timeline article file.
The timeline.txt file houses all of the timeline articles in this one file. The output filenames are within the 〈articl〉 tag. The format follows the general pattern. Some of the older entries have images entered as HTML and need re-coding to the generic style.

Part of the recollections information.
All the recollections appear in this one file.
Vintage Adverts
Extract of the adverts text file.
The advert.txt file resides in the main museum directory and is processed with a dedicated piece of software.
〈advert〉 this tag is followed by the output filename and always exists.
〈=stop=〉 the stop tag is the record end and has no data associated with it.
〈titles〉 A brief description of the item(s) advertised.
〈issues〉 here is given the publication that the advert appeared in together with the date of publication.
〈valves〉 present when a specific valve is advertised. The wording is standardised to Valve Advertised: or Valves Advertised: or CRT Advertised: followed by the Type designation of the valve or valves. If the valve referenced is present within the museum the link structure is typed into the file.
〈extras〉 Any additional text or images appear as individual extras lines.
The valves and extras tags are inserted when required.
Vintage Boxes
The start of the boxes text file.
The boxes.txt file resides in the main museum directory and is processed with a dedicated piece of software.
〈=boxx=〉 this tag is followed by the output filename and always exists.
〈=stop=〉 the stop tag is the record end and has no data associated with it.
〈exhibs〉 this tag is optional and gives the link to the valve exhibit and is followed by the word exhibit.
〈=text=〉 A brief description of the box. For subsequent paragraphs the tag is repeated.
〈boxpic〉 this tag contains the image calls. The presentation of the boxes is now standardised. Image a is 600 px high and shot on a corner. Images b to e are the four sides and also 600 px high - the pictures are reproduced at full size. The reproduce at full size is denoted by the 0 after the caret mark. Images f and g are the box ends. The images are saved as 400 px high and reduced for the output to 300 px. The figure 1 after the caret mark denotes this format. Additional images either 600 px wide or high follow as required.
Master Spreadsheet
In the main museum directory is the Excel file Master Equivalents and Timeline file. This file consists of several workbooks. The feature of all the workbooks is that they are never sorted, the order of the rows defines the output sequence. All editing is carried out within the Excel file and saved to disc once completed. The files used by the museum software are all .CSV flat files. Care has to be taken when making the CSV files that the main Excel file integrity is maintained.
Making the CSV file. Open the fully saved Excel file and select the workbook to be saved in CSV format. Use the Save As function and select the format as .CSV. Then select the file name to be used. Hit save, answer yes then OK. This makes the .CSv file. Then close the excel file - do not save otherwise the multi-workbook format will be lost. Repeat for each CSV file to be made.
Master Equivalents

The equivalents workbook - showing the filename row.
Each row has four fields or columns and there are two types or rows. A row commencing with an @ indicates the presence in field one of an output filename. The other fields are undefined and can contain comments. Files are closed by the presence of a new file name or the end of the file. The other row type is the wanted data.
The equivalents file was first created in the year 2000 and since then has been extended with sub-fields as extra material has been added.
The equivalents data is used for the equivalents indexes as well as being added to individual exhibits in the main database rebuild program.
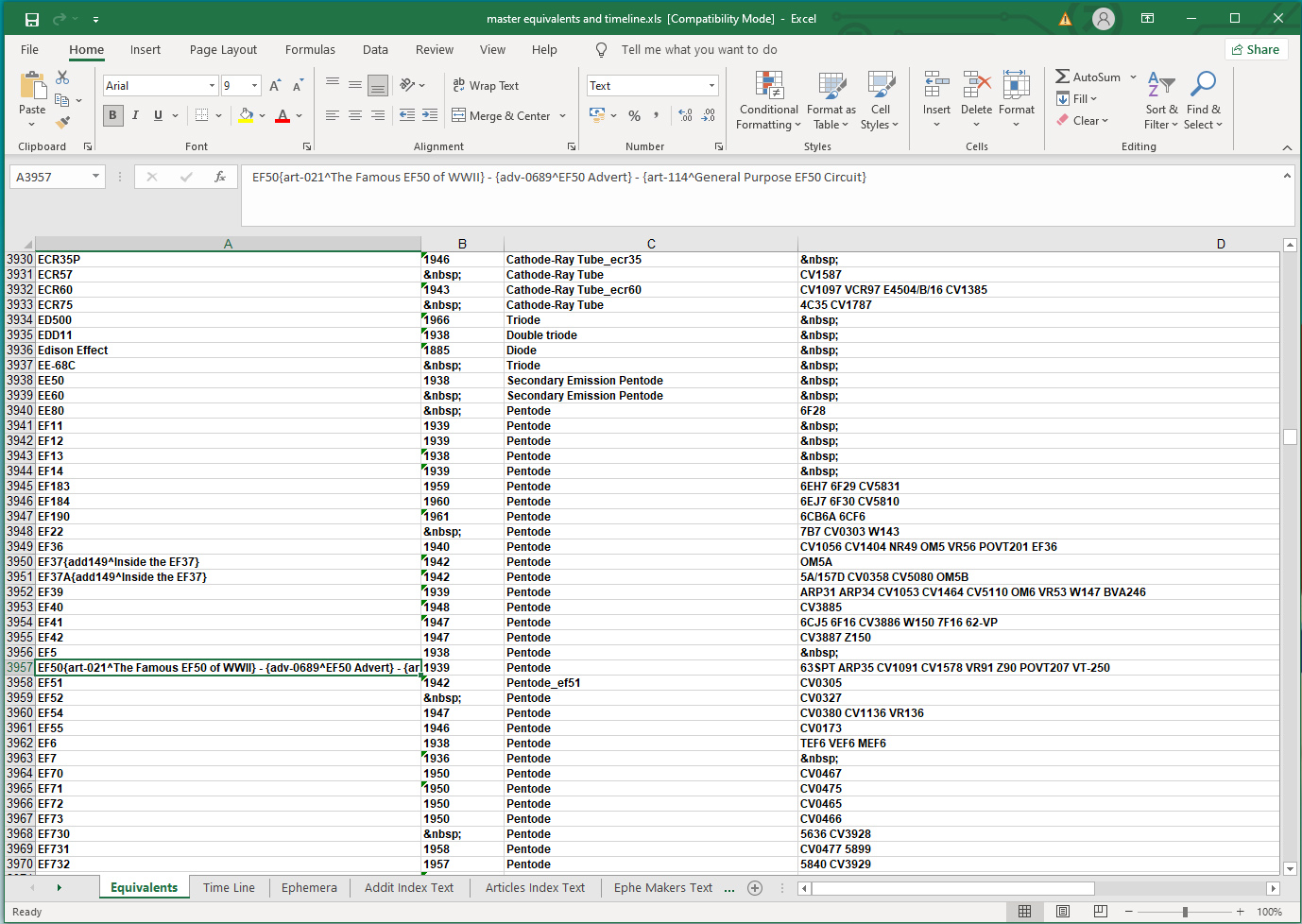
The equivalents workbook - showing the optional sub-fields.
Field One: This lists the Type designation. The presence of one or more standard format links in this field specifies material for the heading box in the 'more box' file where multiple version of the Type exist.
Field two: The year of introduction where known or the HTML non breaking space to denote an empty field.
Field three: The valve electrode system e.g. Pentode. Where a PDF data-sheet has been located for a valve but no example exhibit or proforma exhibit is present the presence of the PDF is indicated by including an underscore after the electrode system. In the case of the EF51 the _ef51 denotes the presence of ef51.pdf in the pdf directory and this will appear in the equivalents index.
To place a link in structure field in the htm file, the link goes in field 3 with the character ~ added. I.e art-369 at the start of the A's and E's is entered as brece ~art-369 shove text brace.
Field four: these are the equivalent Types separated by a space. An empty field is given by the HTML for a non-breaking space.
Timeline
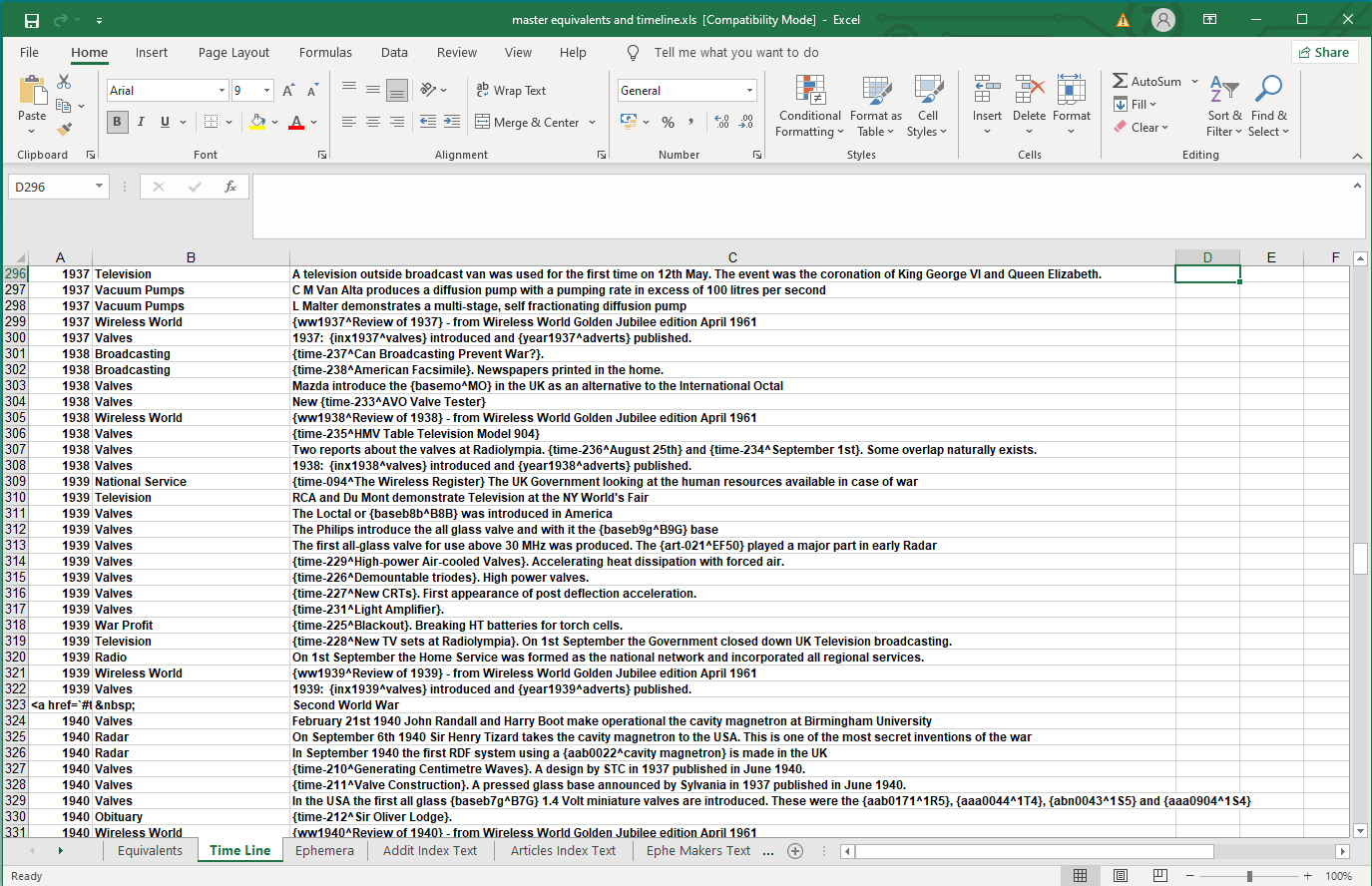
Timeline Page Data.
The timeline workbook has three fields and one row type. To offer a few jump points in the right hand margin of the output file there are a few rows that contain the HTML for a link. In these few rows the second field contains a non breaking space entity and the third field has the heading text.
The standard time-line entry has the date in field one, the type of event in field two and the information in field three. Field three can contain zero, one or many links in the standard museum format. Normally these links refer to the timeline articles.
Ephemera
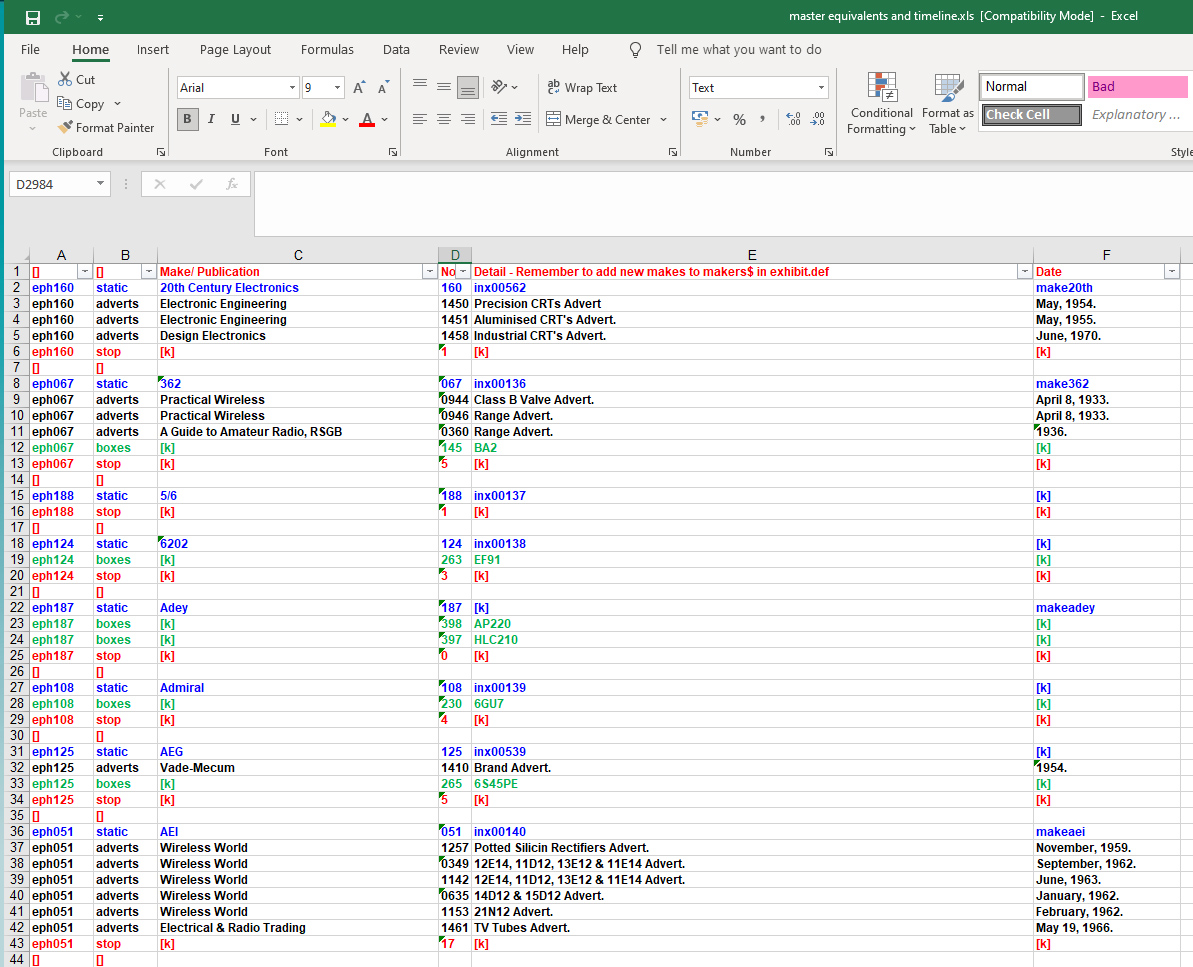
The master ephemera workbook.
The ephemera workbook provides the index data for the Vintage Adverts and Boxes pages where the makers name appear in alphabetical order and re-sellers names are italicised. The ephennn tag is a second master key to the database system and the valve exhibits are linked by replacing the text name i.e. Mullard with {ephe015^Mullard} when the exhibit text files are validated and output as the master file - exhibit.csv.
The workbook consists of five row types and each row has six fields.
Row Type one: Coloured red. This is for visual separation of the entries only and the first line gives the field headings.
Row Type Two: Coloured Blue. Field one is the unique reference and appears as eph and three digits including leading zeros where appropriate. To find the next reference number to allocate, the pull-down tab at the top will show all the existing lines in order. A new entry is thus the next number. Field two indicates the type of record present in this row and is always the word 'static'. Only one static row exists for each maker. Field three is the company name as text. Field four is the unique maker reference number as three digits. Field four is the index number of the exhibits list for that make or [k] if no exhibits are held. The format is always inx followed by five digits when present. Field six is the filename of the descriptive file for that make or [k] to indicate no file present.
Row Type three: Coloured black. This row type is present zero, one or many times and forms the advert descriptions. Field one is the unique reference. Field two is the record type tag 'adverts'. Field three is the name of the publication the advert appeared in. Field four is the four digit number of the advert page information in the adverts.txt file. Field five is the description. Field six is the date of publication. The format is month (day), year. This constant format is used to extract the four digit year for the adverts by year index.
Row Type four: Coloured green. Field one is the unique maker reference. Field two is the row type indicator, in this case 'boxes'. Field three is [k] to denote that it is not used. Field four is the three digit number of the box description in the boxes.txt file. Field five is the name of the valve that went into the box. Field six is [k] to denote that the field is not used.
Row Type five: Coloured red. Field one is the unique maker reference. Field two is the row type and in this case the mandatory 'stop' field terminates a maker's set of entries. Field four contains a snapshot from August 2021 of the number of valve exhibits held. This is used to order the maker Name tags for the validation look-up file and thus place the most used tags at the top of the list. The rest of the fields are set to [k] as they are not used.
Additional Technical Features Index
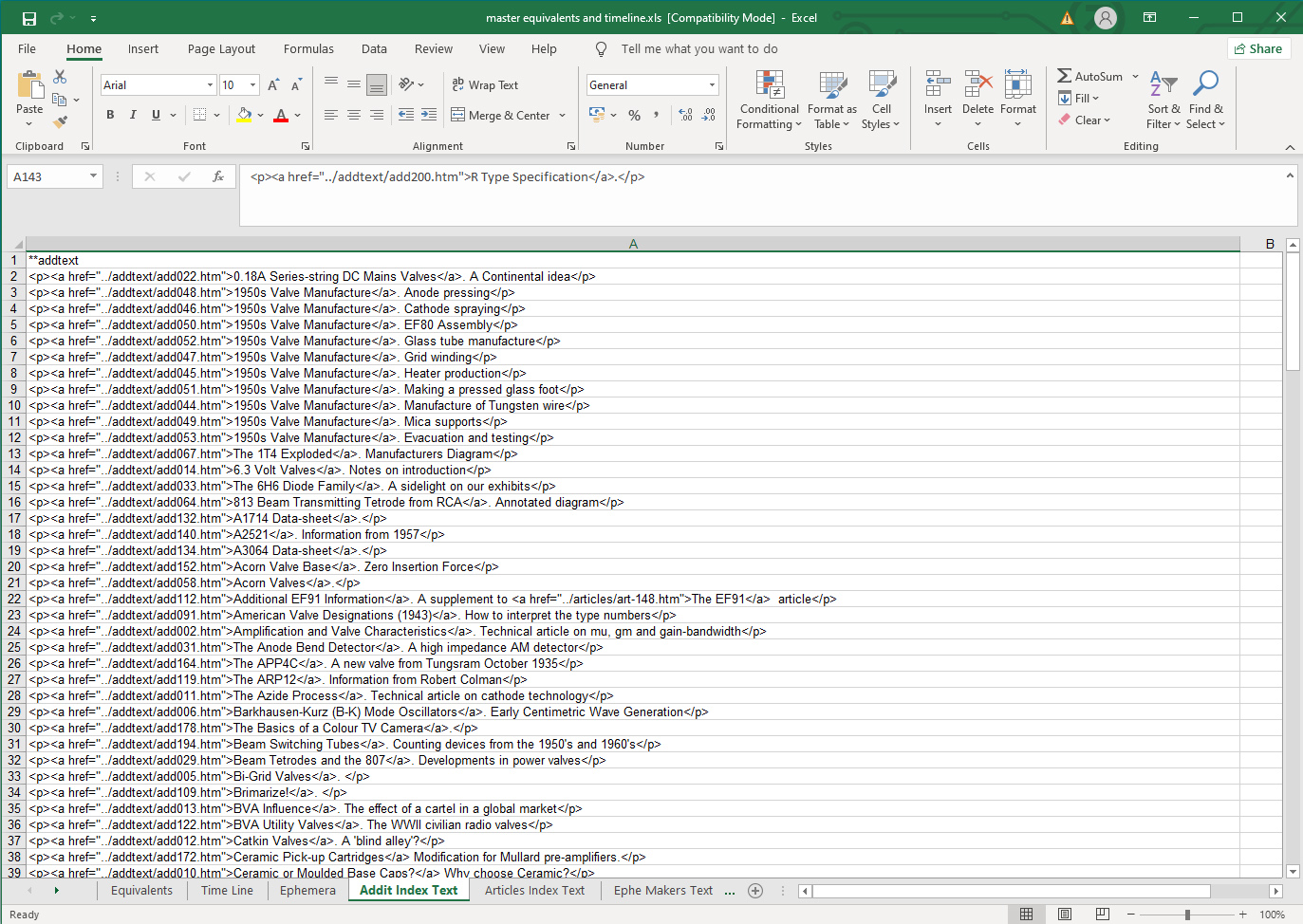
Technical Features Index.
This workbook contains the titles and links, as HTML, to the additional technical features articles.
The first row is the output filename and is denoted by a pair of asterisks at the start.
The other rows have the explicit link information and article title together with the HTML typography tags.
This file replaced an explicit HTML page with this set of records and an HTML page template. The software adds spaces every five entries for clarity. Updating manually was a slow process.
Main Index headings Files
One of the classified indexes.
Essentially this is a mapping and headings file combined. The indexing process places the appropriate data into the named files allowing the information to appear in the same place with each iteration of the museum. At processing time the list is joined by the list of makers. The latter generated from the Ephemera data. The output classified index headings file contains makes as well as valve characteristics as all the index build comes from a common program. The file main-inx.new is edited to remove the maker section and then renamed main-inx.htm for publication. Clumsy, but currently a legacy of the 2015 software.
These rows are HTML lines for merging with a page template file. zero, one or many standard links appear before the href tag with a space between the link and the tag. These extra links form the right hand extras menu for the index.
Other classified index headings files.
These are present in the workbook and operate in the same way as the example above.
Collections Index

Index to Museum Collections.
Functionally identical to the above examples. This list is merged with the HTML page containing the links to external sites and in the merging adds the typography.
Processing
The rebuild after editing process is managed by the program NVM-Edit.exe that is also the database edit controller. The operation commences by running a batch file insert-heads.bat. For exhibit editing the .exb files are not deleted, for a full rebuild run they are removed to avoid duplicates.
The edit aspect of the controller requires a valid file name to work with aaa1234 etc. The notepad++ program and the file are loaded - virtually instantaneously. When editing of a file is complete it is saved and closed. Then the notepad++ program is closed. This action passes control back to the main program. The program then builds the output .csv file for the single record and validates the data in the process - a batch process. If error free the control program returns to wait for a new file name. If the data is faulty the notepad++ program is loaded with an error file. Note of the issues are taken and the file closed together with notepad++ thus return to the control program. The exhibit is presented for correction.
When editing is concluded by typing 'bye' at the prompt the program goes on to ask if the rebuild should take place. A series of N answers are required to finally exit. For a full rebuild the .exb files are removed and the edit phase by-passed. The rebuild questions are answered in the affirmative. The exhibit files have two flavours one for the friends site and SCHC card and the other for the r-type.org site.
As of August 2021 the files are kept on the h: drive in the museum directory and sub-directories. Backups exist in several sites and formats.
|